チームで一緒に働いていると、こんな場面はありませんか?
- 「あの人、なんであんなに気にしているんだろう?」
- 「私は全然気にならないのに、なんで落ち込んでいるんだろう?」
- 「同じ変化のお知らせなのに、チームの反応がバラバラ…」
こうした「反応の違い」は、悪意があるわけでも、誰かが間違っているわけでもないはずです。その背景には、それぞれが無意識に大切にしている「核心的なニーズ」の違いがあります。
今回、株式会社イノベーションさまのSRE・開発・QAの3部署から8名にお集まりいただき、「お互いの核心的ニーズを理解し合うワークショップ」を開催しました。およそ2.5時間のセッションです。
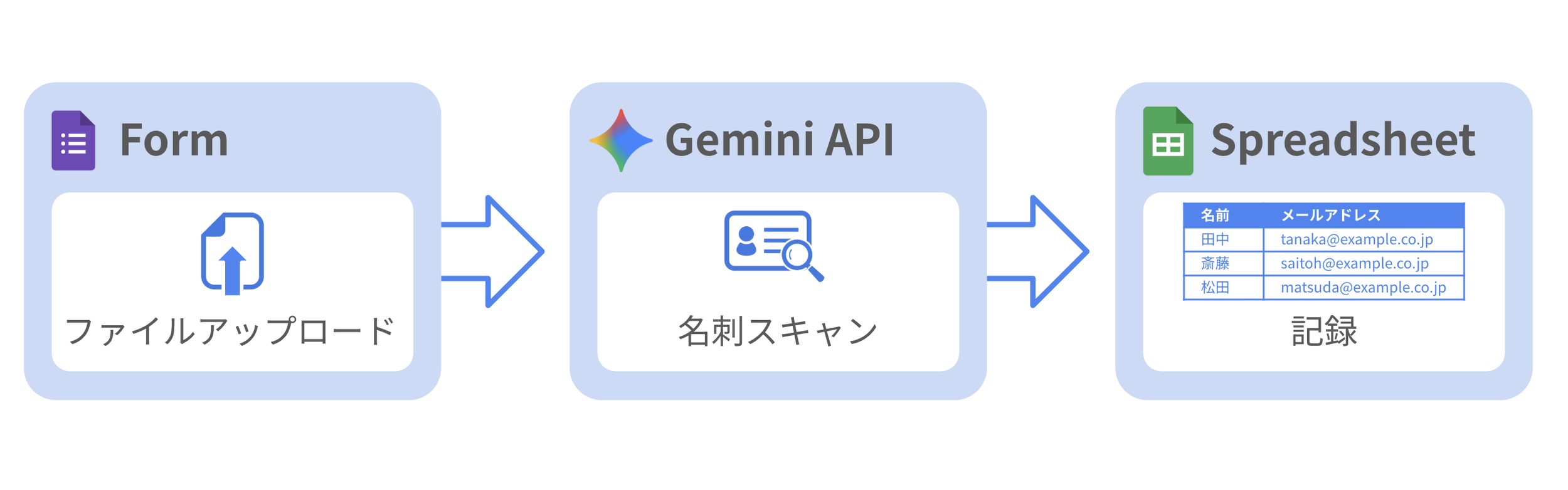
BICEPSフレームワークとは?
ワークショップの軸となったのは、BICEPS(バイセプス)フレームワーク です。レジリエントマネジメントという書籍でも紹介されており、心理学者のPaloma Medinaさんが研究をもとに開発した、人間の核心的なニーズを6つに整理したモデルです。
| 頭文字 | キーワード | 説明 |
|---|---|---|
| B | Belonging(帰属) | コミュニティや仲間とのつながり |
| I | Improvement(向上・成長) | 成長や進歩を感じること |
| C | Choice(選択) | 自分の仕事や人生を自分で決められること |
| E | Equality / Fairness(平等・公平) | 公平な扱いと情報の透明性 |
| P | Predictability(予測可能性) | 一貫性と適度な安定 |
| S | Significance(意義) | 自分の価値や貢献の実感 |
重要なのは、人によって大切にするニーズは異なるということです。さらに同じニーズ(たとえば「選択」)でも、「柔軟性」「自律性」「意思決定への参加」と、大切にしている側面が異なります。
ワークショップの流れ
1. BICEPSの紹介 —— 「席替え」を例に
導入では、おなじみの「席替えのお知らせ」を題材にワークショップをスタートしました。
- Aさんの反応:「やった〜!新しい環境だ!」→ Improvement(変化=成長の機会)
- Bさんの反応:「えっ、今のままがいいのに…」→ Belonging(つながりが切れる)+ Predictability(環境が変わる不安)
- Cさんの反応:「誰が決めたの!相談なしなの?」→ Choice(決定に関われない)+ Equality(プロセスが不透明)
同じ出来事への反応がこんなに異なるのか、という驚きとともに、「席替えの例がわかりやすくて良かった」とのありがたいお声が参加者から寄せられました。一方で、「各ニーズの似ている部分が分かりにくかった」「他のツールとの違いがもう少し知りたかった」というフィードバックもあり、奥深いフレームワークだからこそ説明が難しい部分もあるなと感じつつ、もう少し私の実体験を交えてご説明できれば良かったのかなという改善のヒントもいただけました。
2. 自分の核心的ニーズ診断
BICEPSセルフチェックシートを使って、20の問いに向き合う時間を設けました。「べき」ではなく「実際」や「直感」を大切にしながら自分のTop3ニーズを探ります。
「普段感じていることを言語化して認識できたのが良かった」「改めて自分のことを知る良いきっかけになった」という声があった一方、「設問で迷ってしまい、あまり結果に差が出なかった」という声もありました。深く向き合うほど正直に悩んでしまう、という意味では、それ自体が自己理解のプロセスかもしれませんし、もう少し設問自体の改善やタイムボックスの改善が必要かもしれません。

3. お互いのニーズを知る —— ここからが本番
小グループに分かれて、自分のTop3ニーズ・大切にしている側面・具体的なエピソードを共有し合いました。その後、チーム全体でBICEPS分布を可視化しました。今回のグループでは、S(意義)とB(帰属)が特に多く、P(予測可能性)もまとまった分布でした。
「他のメンバーのこと、特に普段あまり深く関わらない人たちのことが知れて良かった」 「同じ事象を例に出しても感じているニーズが異なっているのが面白かった。メンバーの話を聞いて『そういう考え方もあるのか』と感心したし、自分にない観点を吸収する機会になった」
部署を超えたこの対話こそ、今回のワークショップの核心だったので、参加者のみなさまの対話がとても活性化し、エネルギーに満ちているように見受けられたため、開催者としての喜びに浸っていました。


4. ケーススタディ —— BICEPSを実践へ
「新しいプロジェクト管理ツールをチーム全体に導入するとしたら?」という具体的なケースで、各ニーズを持つ人への配慮の仕方を考えました。
- 帰属が強い人には:みんなが使うという安心感を
- 選択が強い人には:使い方の柔軟性や選択肢を
- 平等・公平が強い人には:公平な研修機会と情報共有を
- 予測可能性が強い人には:いつから、どんなルールかを明確に
日常の意思決定や変更の伝え方が、こんなにも変わるのかと実感できる時間になったのではないかと思います。
アンケートから見えたこと
ワークショップ後のアンケート(7名回答)の結果をそのままお伝えします。
良かった点
- 全体満足度5(最高):回答者の71%
- 知人に勧めたい(スコア9〜10):回答者の86%
- チームメンバーへの理解が深まった(スコア4〜5):回答者の100%
- チームの行動規範を実践したい(スコア4〜5):回答者の100%
改善の余地があった点
- 「BICEPSでないといけない理由が分かりにくかった」—— 類似ツールとの比較説明が欲しかった、という声がありました
- 「核心的ニーズという言葉があまりピンと来なかった」—— 言葉の難しさを感じた方もいたようです
- 「チームの行動規範作りのセクションは理解が難しかった」—— 駆け足になりがちな後半のワークの充実は次回の課題です
参加者の声(自由記述):
- 「意外な人が自分と同じような考えだと気付けたり、そうじゃなかったりして面白かった」
- 「お互いのニーズを知ることで、コミュニケーションの仕方が変えられそう」
- 「家庭でも使えそう。子どものニーズを分析してみたいです」
こんなチームにこそ、試してほしいと思っています
今回参加いただいたのは、SRE・開発・QAという異なるミッションを持つ3チームのメンバーです。「普段は深く関わらない」という関係性の中でも、ニーズを語り合うことで短時間で一気に距離が縮まっていると嬉しいです。
このワークショップは、こんな状況のチームに特に効果的だと思っています。
- リモート・ハイブリットで関係性が薄いと感じている
- 新メンバーが加わった
- 組織変更があった
- 心理的安全性をもっと高めたい
もちろんまだ改善できる部分もあるし、フレームワーク自体に慣れが必要な側面もあると思います。でも「違いを尊重し合える関係性の第一歩」としては、十分に手応えを感じられたセッションで、「違い」を尊重し合える関係性が、チームの力を引き出す第一歩になるんじゃないかなと私は思っています。
自分たちのチームでも試してみたいと思った方、あるいは「どんな内容か詳しく知りたい」という方は、ぜひお気軽にご連絡ください。