


みなさんこんにちは。KEYチームの武永です。
先日とある学生さんから以下のようなメールを貰いました。
武永さんのGebのブログを読んでGebに興味が出てきて
実際に動作させてみたいと思ったのですが、 環境構築の仕方が分からず動かせていない状況です。
メールでもブログでもいいのでご助力いただけると幸いです。
詳しく状況を聞いてみると
「いつもはRubyを触っているが、何から手をつけていいのか分からない」
「私がどのような環境で動かしているのか興味がある」との事でした。
こういう連絡が来るとは思っていませんでした。
初歩的な情報でも参考になる方は多いのかなと思ったので今回は環境構築から 公式のサンプルコードの実装と説明の日本語訳 + 簡単なコードの説明を書いていこうと思います。
※英語は得意ではないので訳が100%正しいものとは言えないです。。。
使用する環境
- Mac OS X Yosemite
- Java8
- IntelliJ IDEA14.1 Community Edition
環境構築
さて、さっそく環境構築を進めていきましょう。
とは言っても環境構築自体はGebはGroovyなので全く難しくありません。
※Javaのインストールは省略します。
IntelliJ IDEA14 インストール
既にIntelliJ IDEAがインストールされている方は読み飛ばして大丈夫です。
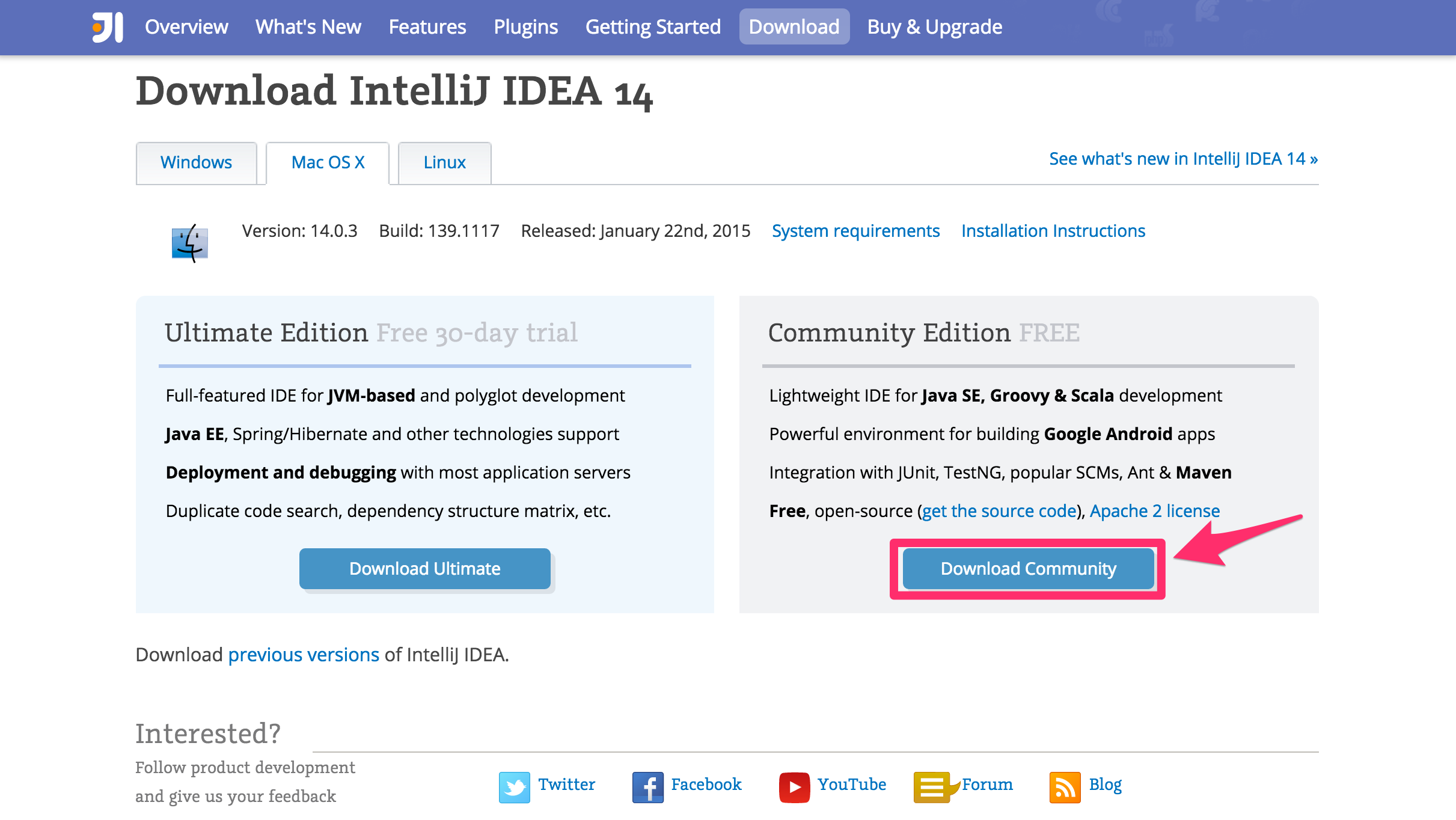
- https://www.jetbrains.com/idea/download/
上記へアクセス - 「Download Community」ボタンを押下
「Ultimate Edition」でも問題はありません。
ダウンロードが始まります。 - ダウンロードされた「ideaIC-14.1.4.dmg」を開く
Intellij IDEA を アプリケーションへドラッグアンドドロップ

IntelliJ IDEAは標準でGroovyに対応しているので準備完了です。
プロジェクト作成
- new project → Maven → next

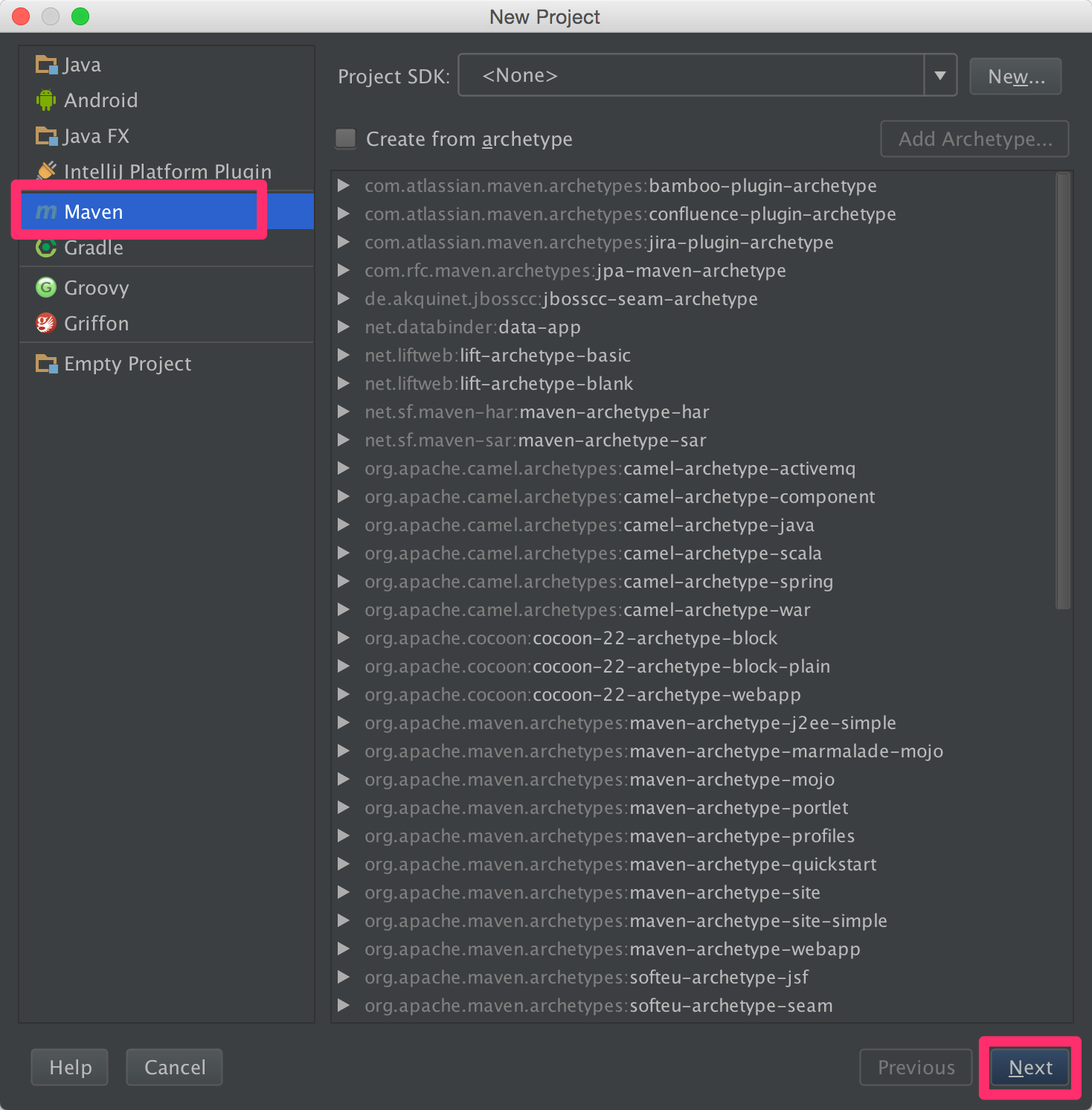
Project SDKが設定されていない場合は用意したJDKを選択しておいてください。 JDKの場所はデフォルトならば [/Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home] 上記のようになっています。
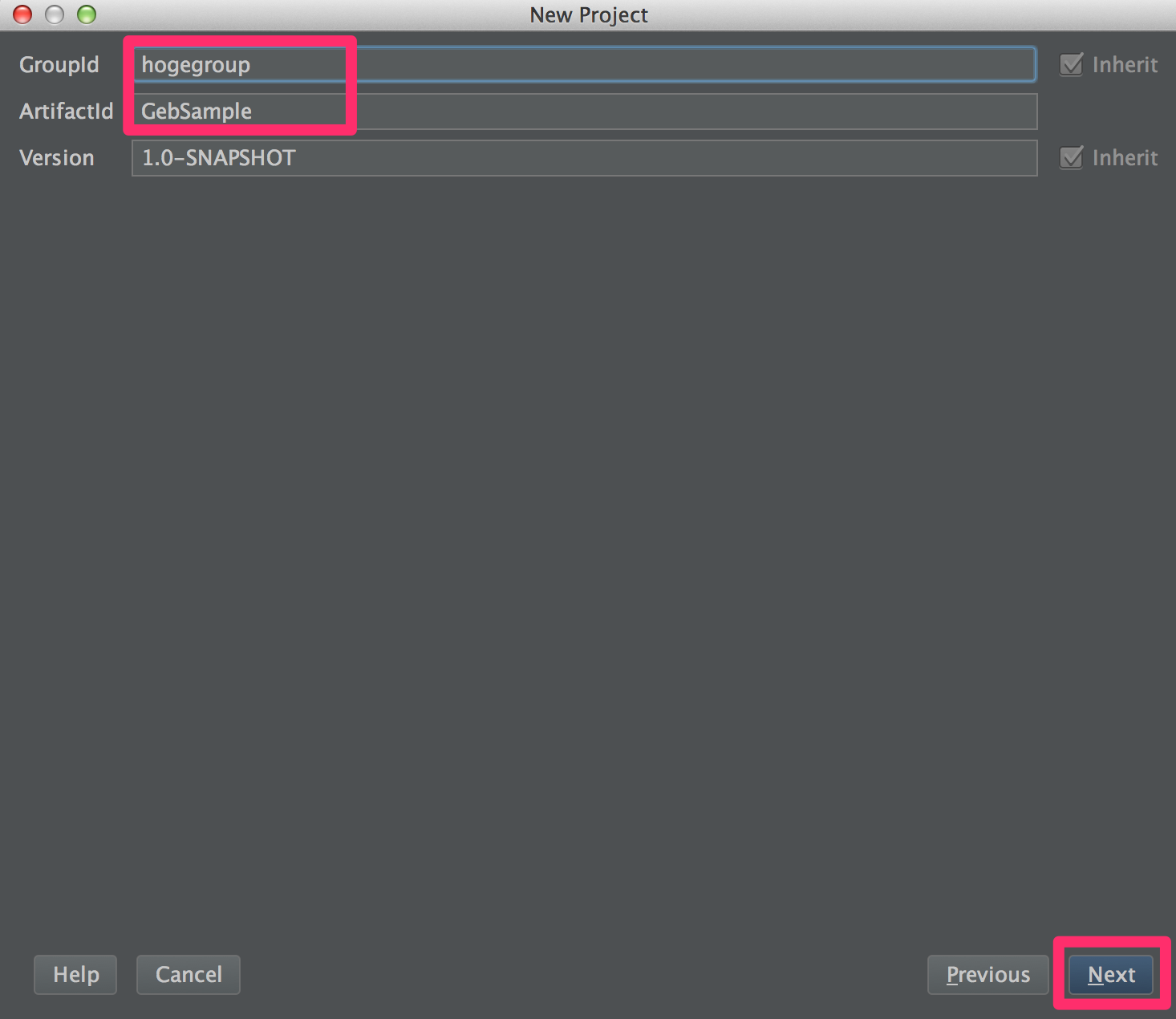
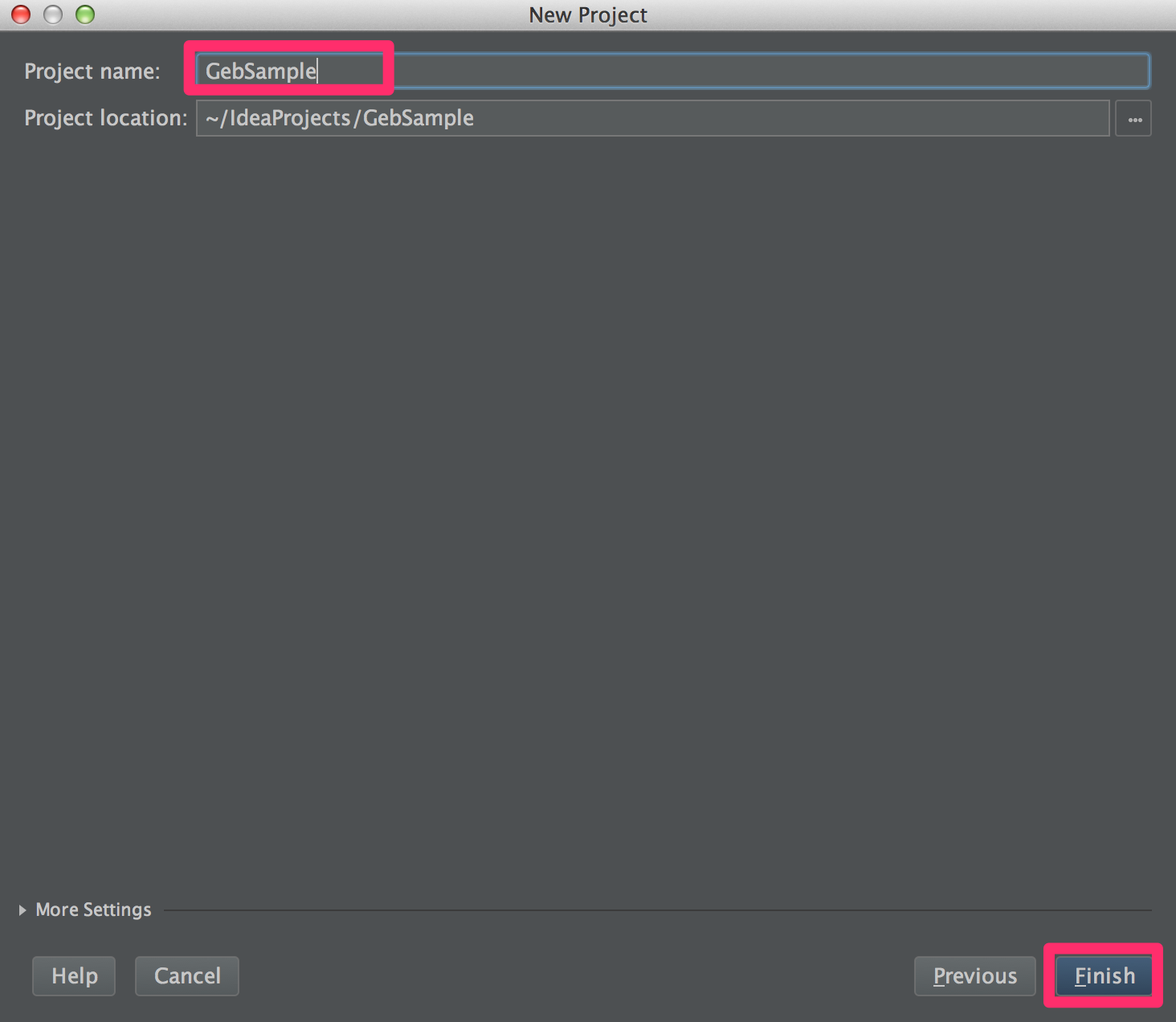
- GroupIdとArtifactIdを入力 → next → ProjectNameを入力 → finish
pom.xmlの編集
pom.xmlを以下のとおりに編集します。
サンプルコード実装
Gebが動く環境は整ったので実装に入ります。
以下の様に「module」と「page」Packageを作成します。
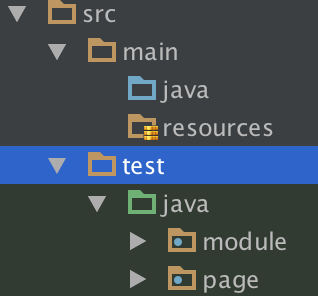
- module配下に「SelectableLinkModule.groovy」を作成します。
- module配下に「HighlightsModule.groovy」を作成します。
- page配下に「GebHomePage.groovy」を作成します。
- test直下に「GebHomepageSpec.groovy」を作成します。
以上でサンプル実装終了です。
では実際に動かしてみましょう。
「GebHomepageSpec」を左クリック → Run 'GebHomepageSpec' をクリックで実行できます。

実行結果がこちらの動画です。
最後に
まさか私のブログを読んでメールを送ってきてくれるとは思っていなかったのでメールを受け取った時には非常に驚きました。
個人的にはメールを送ってくれた方には是非会ってみたいなと思っています。
今回の記事でGebをとりあえず動かしてみようと思ってくれる人がいると幸いです。




